
Track word occurrence by sentiment
Tracking word sentiment
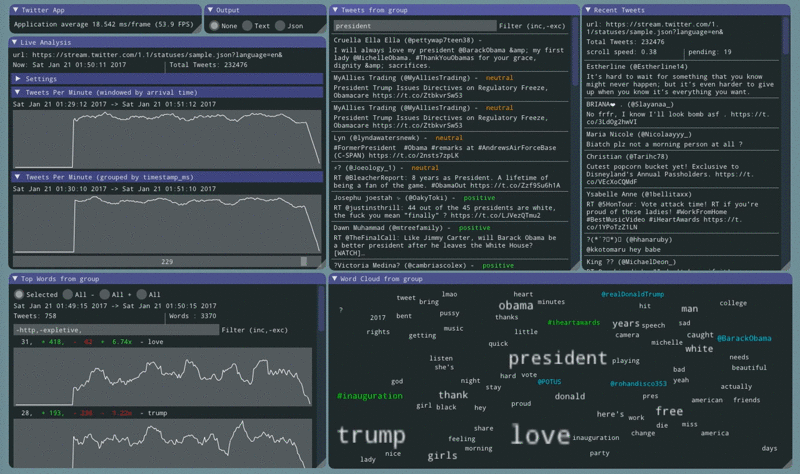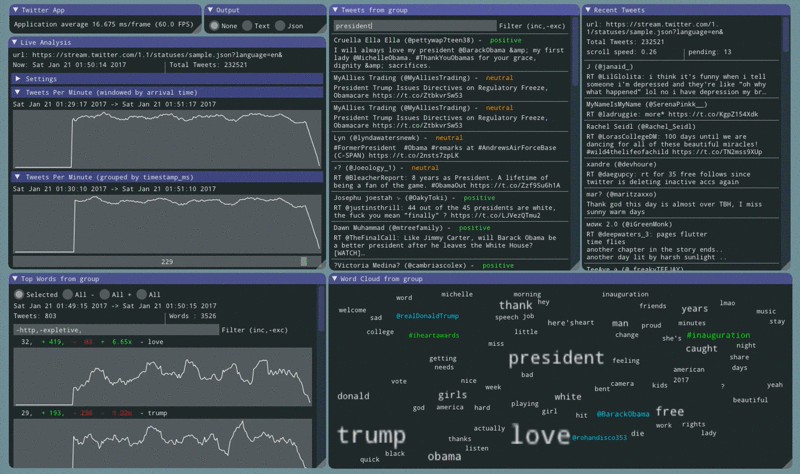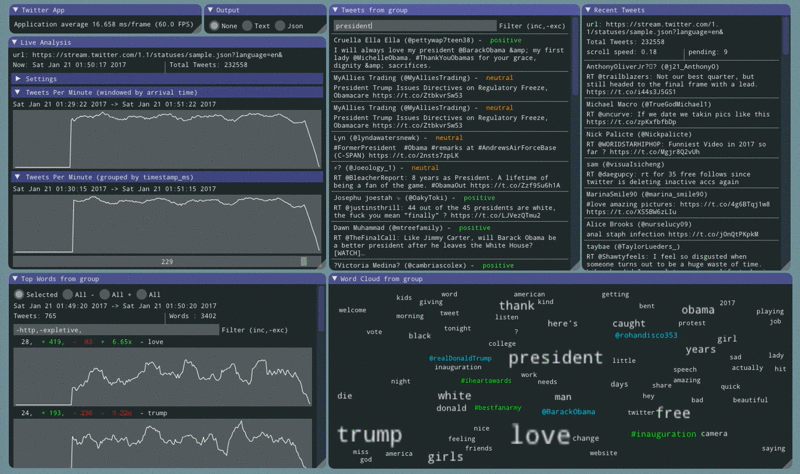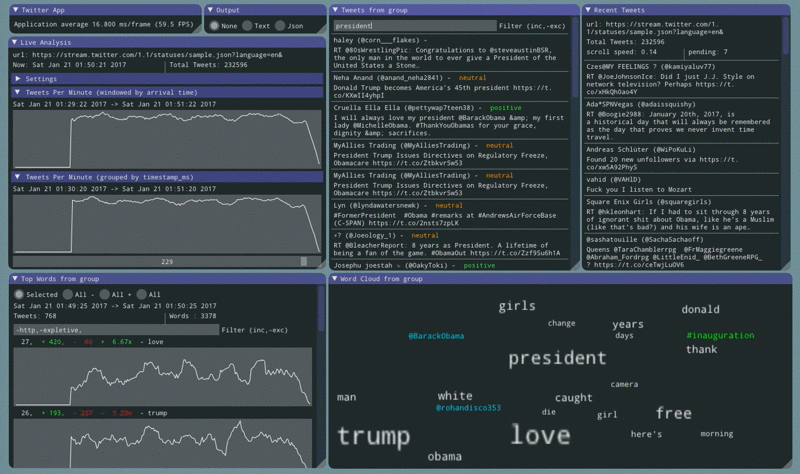
Sentiment information for each tweet is nice. The next step is to count how many times each word appeared in a negative tweet and how many times the same word appeared in a positive tweet.
The word ‘love’ is consistently shown to be in the top 2 words across all tweets. After adding this code the app shows that ‘love’ occurs 8x more in positive tweets then in negative ones.
Other notable words:
- ‘work’ is 3x more likely to be used in a negative tweet
- ‘wanna’ is 8x more likely to be used in a negative tweet
- ‘thank’ is 3x more likely to be used in a positive tweet
Collecting sentiment per word
Adding maps to the Model that hold counts of positive tweets and negative tweets that contain each word was simple.
This was added to the Reducer produced when a sentiment call completes.
for (auto& word: get<1>(b).data->words) {
sentiment["Sentiment"] == "negative" && ++m.data->negativewords[word];
sentiment["Sentiment"] == "positive" && ++m.data->positivewords[word];
}
Display sentiment per word
Showing the actual counts for the top words is good. This code does that and also displays a fraction that shows the relative frequency for the word between positive and negative tweets. The relative frequency was used to derive the data about ‘wanna’ above.
auto positive = m.positivewords[w.word];
ImGui::TextColored(positivecolor, " +%4.d,", positive); ImGui::SameLine();
auto negative = m.negativewords[w.word];
ImGui::TextColored(negativecolor, " -%4.d", negative); ImGui::SameLine();
if (negative > positive) {
ImGui::TextColored(negativecolor, " -%6.2fx", negative / std::max(float(positive), 0.001f)); ImGui::SameLine();
} else {
ImGui::TextColored(positivecolor, " +%6.2fx", positive / std::max(float(negative), 0.001f)); ImGui::SameLine();
}
Sorting words
The words are already sorted by frequency. With a little more code they are also sortable by positive frequency or negative frequency.
if (scope == scope_all_negative) {
data->scope_words = &data->negativewords;
data->negativewords = model.negativewords |
ranges::view::transform([&](const pair<string, int>& word){
return WordCount{word.first, word.second, {}};
});
data->negativewords |=
ranges::action::sort([](const WordCount& l, const WordCount& r){
return l.count > r.count;
});
} else if (scope == scope_all_positive) {
data->scope_words = &data->positivewords;
data->positivewords = model.positivewords |
ranges::view::transform([&](const pair<string, int>& word){
return WordCount{word.first, word.second, {}};
});
data->positivewords |=
ranges::action::sort([](const WordCount& l, const WordCount& r){
return l.count > r.count;
});
}
This is used to drive the top words and word cloud and is also used to pre-filter the tweets list to match the selected sentiment. The result is the ability to explore both the most negative and most positive words and find example tweets that contributed to those designations.