
Counting tweets
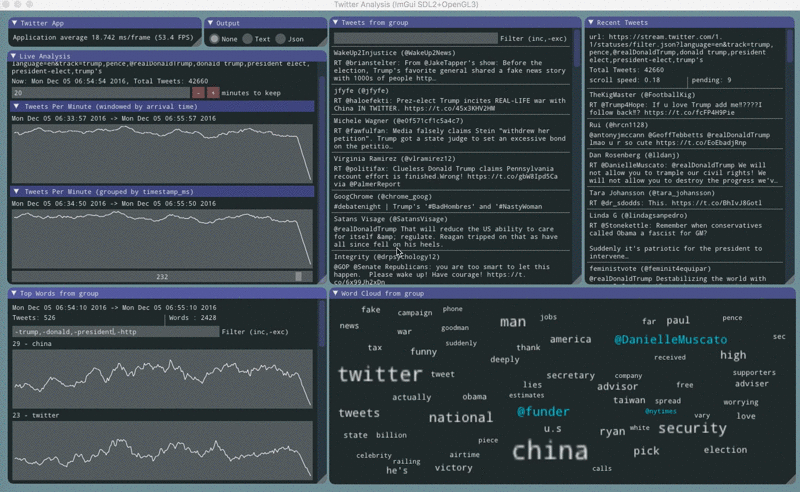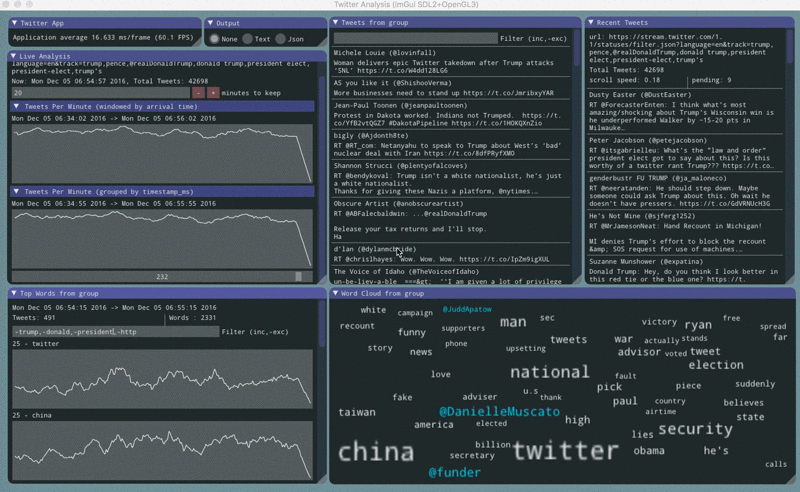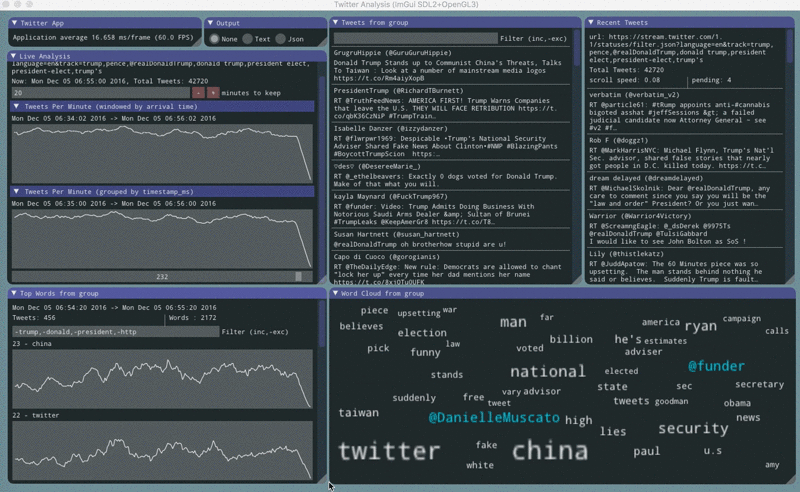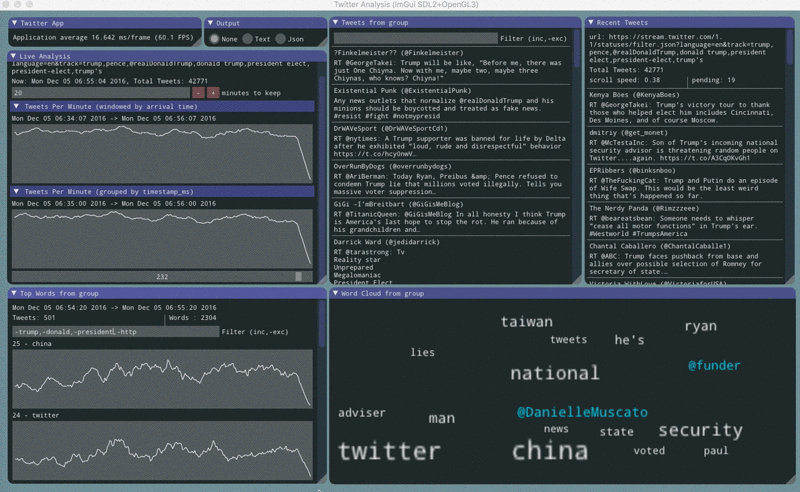
Counting tweets
Counting tweets one of the ways the app processes the data to provide useful functionality. This will finally begin to justify the existance of this app.
The app counts tweets in two different ways. One plot shows tweets counted by their arrival time. Another plot shows tweets counted by their timestamp_ms value.
The plots sometimes show oscillations.
When the arrival plot has oscillations it means that delivery is being interrupted, but often the timestamp_ms plot is unaffected showing that all the tweets that were selected did eventually arrive. This usually appears as a sawtooth pattern.
When the timestamp_ms plot has oscillations it means that twitter’s tweet sampling has been impacted, but usually the arrival plot is unaffected. This usually appears as a sine wave pattern.
count tweets by arrival time
The rxcpp window_with_time() operator will split up the tweets into overlapping windows of time. length is 1 minute and every is 5 seconds. Every 5 seconds a new window will be created that will complete 1 minute later. There are multiple overlapping windows open. Each tweet will be delivered to every window that was open at the time it arrived.
// window tweets by the time that they arrive
reducers.push_back(
ts |
onlytweets() |
window_with_time(length, every, poolthread) |
To start each window, cast now() to seconds to round to the nearest second and use that as the beginning of this window.
auto rangebegin = time_point_cast<seconds>(system_clock::now()).time_since_epoch();
Update the tweet count for this window in the Model
const auto i = duration_cast<seconds>(rangebegin - m.tweetsstart).count()/duration_cast<seconds>(every).count();
++m.tweetsperminute[i];
The rest of the code maintains a limit to the history that is kept in memory.
the complete expression
// window tweets by the time that they arrive
reducers.push_back(
ts |
onlytweets() |
window_with_time(length, every, poolthread) |
rxo::map([](observable<shared_ptr<const json>> source){
auto rangebegin = time_point_cast<seconds>(system_clock::now()).time_since_epoch();
auto tweetsperminute = source |
rxo::map([=](const shared_ptr<const json>&) {
return Reducer([=](shared_ptr<Model>& md){
auto& m = *md;
auto maxsize = (duration_cast<seconds>(keep).count()+duration_cast<seconds>(length).count())/duration_cast<seconds>(every).count();
if (m.tweetsperminute.size() == 0) {
m.tweetsstart = duration_cast<seconds>(rangebegin + length);
}
if (static_cast<long long>(m.tweetsperminute.size()) < maxsize) {
// fill in missing history
while (maxsize > static_cast<long long>(m.tweetsperminute.size())) {
m.tweetsperminute.push_front(0);
m.tweetsstart -= duration_cast<seconds>(every);
}
}
if (rangebegin >= m.tweetsstart) {
const auto i = duration_cast<seconds>(rangebegin - m.tweetsstart).count()/duration_cast<seconds>(every).count();
// add future buckets
while(i >= static_cast<long long>(m.tweetsperminute.size())) {
m.tweetsperminute.push_back(0);
}
++m.tweetsperminute[i];
}
// discard expired data
while(static_cast<long long>(m.tweetsperminute.size()) > maxsize) {
m.tweetsstart += duration_cast<seconds>(every);
m.tweetsperminute.pop_front();
}
return std::move(md);
});
});
return tweetsperminute;
}) |
merge() |
nooponerror() |
start_with(noop));
count tweets by timestamp_ms
This splits the words from each tweet on a background thread and then sends.
// group tweets, that arrive, by the timestamp_ms value
reducers.push_back(
ts |
onlytweets() |
observe_on(poolthread) |
rxo::map([=](const shared_ptr<const json>& tw){
auto& tweet = *tw;
auto text = tweettext(tweet);
auto words = splitwords(text);
return Reducer([=](shared_ptr<Model>& m){
auto t = timestamp_ms(tw);
updategroups(m, t, tw, words);
return std::move(m);
});
}) |
nooponerror() |
start_with(noop));
splitwords()
A pretty simple function that took a few iterations to get into a useful state just for English text. A really good solution would get very complex.
The approach here is to split the text on whitespace first.
static const string delimiters = R"(\s+)";
auto words = split(text, delimiters, Split::RemoveDelimiter);
For each string - remove some leading and trailing punctuation
while (!word.empty() && (word.front() == '.' || word.front() == '(' || word.front() == '\'' || word.front() == '\"')) word.erase(word.begin());
while (!word.empty() && (word.back() == ':' || word.back() == ',' || word.back() == ')' || word.back() == '\'' || word.back() == '\"')) word.resize(word.size() - 1);
Replace some common expletives with a fixed string
word = regex_replace(word, expletives, "<expletive>");
‘stop’ words are words that should be ignored because they are too generic and common to represent a topic or trend. I got a start on my list here and then added more words that did not convey much meaning in the word cloud.
words.erase(std::remove_if(words.begin(), words.end(), [=](const string& w){
return !(w.size() > 2 && ignoredWords.find(w) == ignoredWords.end());
}), words.end());
Use Range-v3 to filter out word repetition. This prevents tweets that repeat a single word extensively from saturating the word counts.
words |=
ranges::action::sort |
ranges::action::unique;
the complete function
inline vector<string> splitwords(const string& text) {
static const unordered_set<string> ignoredWords{
"rt", "like", "just", "tomorrow", "new", "year", "month", "day",
"today", "make", "let", "want", "did", // ...
};
static const string delimiters = R"(\s+)";
auto words = split(text, delimiters, Split::RemoveDelimiter);
// exclude entities, urls and some punct from this words list
static const regex ignore(R"((\xe2\x80\xa6)|(&[\w]+;)|((http|ftp|https)://[\w-]+(.[\w-]+)+([\w.,@?^=%&:/~+#-]*[\w@?^=%&/~+#-])?))");
static const regex expletives(R"(\x66\x75\x63\x6B|\x73\x68\x69\x74|\x64\x61\x6D\x6E)");
for (auto& word: words) {
while (!word.empty() && (word.front() == '.' || word.front() == '(' || word.front() == '\'' || word.front() == '\"')) word.erase(word.begin());
while (!word.empty() && (word.back() == ':' || word.back() == ',' || word.back() == ')' || word.back() == '\'' || word.back() == '\"')) word.resize(word.size() - 1);
if (!word.empty() && word.front() == '@') continue;
word = regex_replace(tolower(word), ignore, "");
if (!word.empty() && word.front() != '#') {
while (!word.empty() && ispunct(word.front())) word.erase(word.begin());
while (!word.empty() && ispunct(word.back())) word.resize(word.size() - 1);
}
word = regex_replace(word, expletives, "<expletive>");
}
words.erase(std::remove_if(words.begin(), words.end(), [=](const string& w){
return !(w.size() > 2 && ignoredWords.find(w) == ignoredWords.end());
}), words.end());
words |=
ranges::action::sort |
ranges::action::unique;
return words;
}
updategroups()
Add the tweet to each time window group in the Model and update the words counts in each group.
if (searchbegin+offset <= timestamp && timestamp < searchbegin+offset+length) {
it->second->tweets.push_back(tw);
for (auto& word: words) {
++it->second->words[word];
}
}
the complete function
inline void updategroups(
shared_ptr<Model>& md,
milliseconds timestamp,
const shared_ptr<const json>& tw = shared_ptr<const json>{},
const vector<string>& words = vector<string>{}) {
auto& m = *md;
auto searchbegin = duration_cast<minutes>(duration_cast<minutes>(timestamp) - length);
if (!tw) {
searchbegin = duration_cast<minutes>(duration_cast<minutes>(timestamp) - keep);
}
auto searchend = timestamp;
auto offset = milliseconds(0);
for (;searchbegin+offset < searchend;offset += duration_cast<milliseconds>(every)){
auto key = TimeRange{searchbegin+offset, searchbegin+offset+length};
auto it = m.groupedtweets.find(key);
if (it == m.groupedtweets.end()) {
// add group
m.groups.push_back(key);
m.groups |= ranges::action::sort(less<TimeRange>{});
it = m.groupedtweets.insert(make_pair(key, make_shared<TweetGroup>())).first;
}
if (!!tw) {
if (searchbegin+offset <= timestamp && timestamp < searchbegin+offset+length) {
it->second->tweets.push_back(tw);
for (auto& word: words) {
++it->second->words[word];
}
}
}
}
while(!m.groups.empty() && m.groups.front().begin + keep < m.groups.back().begin) {
// remove group
m.groupedtweets.erase(m.groups.front());
m.groups.pop_front();
}
}
mesmerising
This app is mesmerising. I keep it running all day and night. I pull out my laptop when visiting friends and family and just let it run. I keep finding things out by watching the app that only appear on my other information feeds later. I have been adding additional filter functionality that allows me to focus on a trending topic and leapfrog into a deeper understanding of the current moment.