
Parsing json documents from a stream
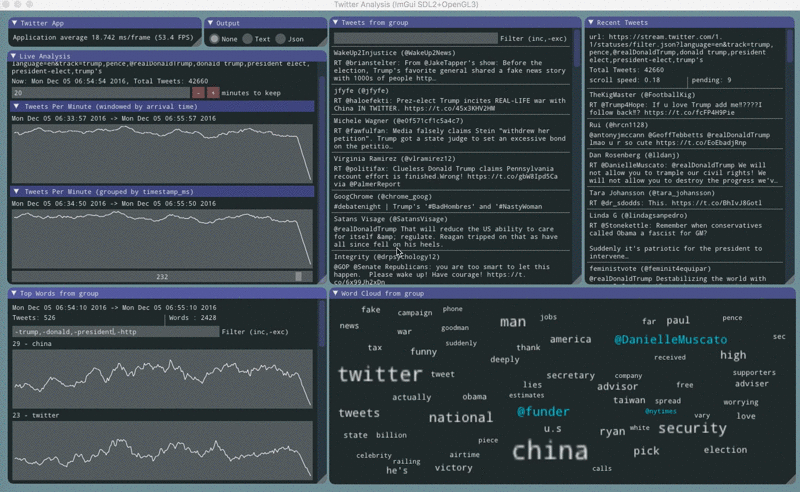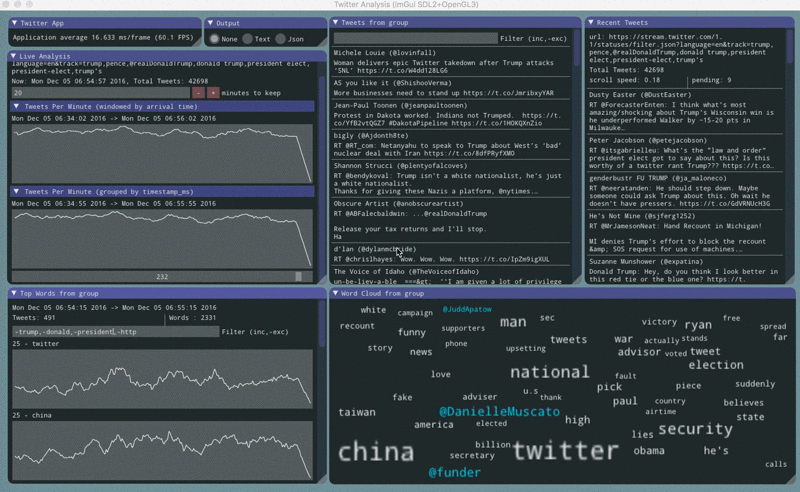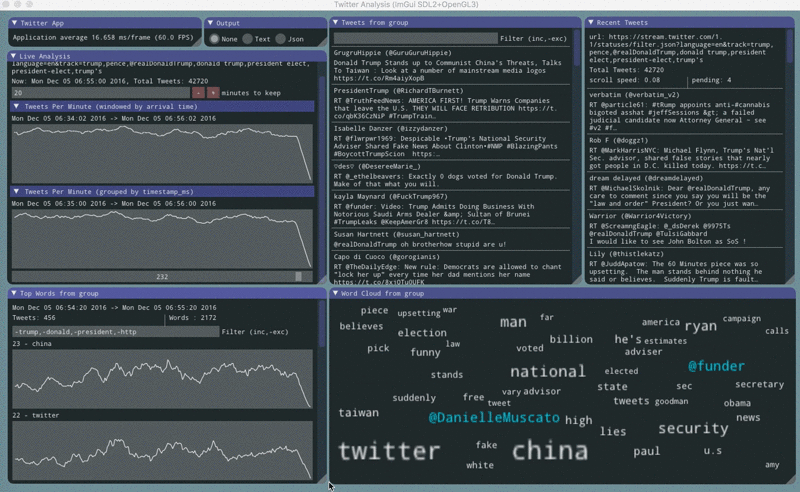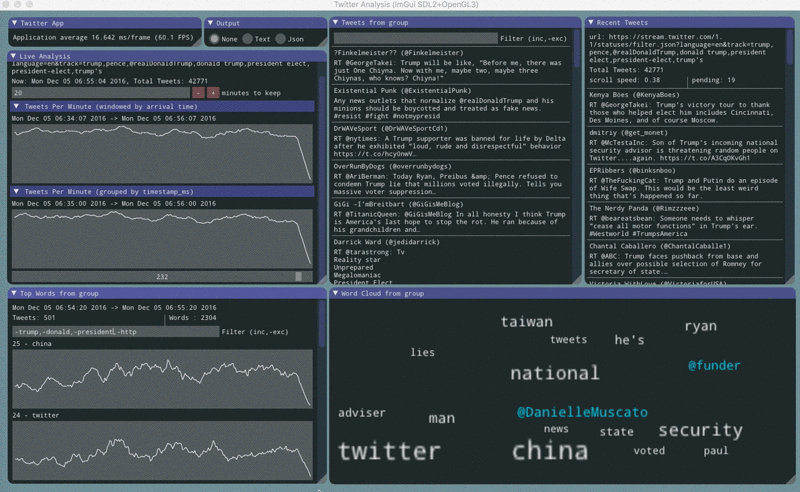
twitter stream contents
The twitter stream api emits json documents delimited by \r\n. Sometimes there will be partial or corrupt json documents. Sometimes there will be empty lines. Empty lines are used as a keep-alive mechanism for sparse streams.
The json parser that I selected does not support streaming natively, so there needs to be code that carves a set of strings into a set of json documents.
parsetweets
parsetweets defines a new rxcpp operator that will take strings in and return json documents.
// parse tweets
auto tweets = chunks | parsetweets(tweetthread);
To find the end of a tweet we need to know when a string ends in \r\n.
auto isEndOfTweet = [](const string& s){
if (s.size() < 2) return false;
auto it0 = s.begin() + (s.size() - 2);
auto it1 = s.begin() + (s.size() - 1);
return *it0 == '\r' && *it1 == '\n';
};
Split each string on \r\n when it arrives.
split()usescregex_token_iteratorto take a string and split it into avector<string>
// create strings split on \r
auto strings = chunks |
concat_map([](const string& s){
auto splits = split(s, "\r\n");
return iterate(move(splits));
}) |
filter([](const string& s){
return !s.empty();
}) |
publish() |
ref_count();
Now create a stream that emits 0 when a string ending in \r\n occurs.
// filter to last string in each line
auto closes = strings |
filter(isEndOfTweet) |
rxo::map([](const string&){return 0;});
Now use closes to signal the begin and end of a window. This will produce a window for each set of strings that make up one json document.
start_with()opens the first window, after which each close also opens a new window.
// group strings by line
auto linewindows = strings |
window_toggle(closes | start_with(0), [=](int){return closes;});
Each window will have 1 or more strings. Now reduce each window to a single string.
sum()concatenates the strings usingoperator+().start_with()is required to prime thesum(), without it there would be an exception for empty windows.
// reduce the strings for a line into one string
auto lines = linewindows |
flat_map([](const observable<string>& w) {
return w | start_with<string>("") | sum();
});
Now filter out strings that are empty or not properly delimited and json parse the remaining strings.
return lines |
filter([](const string& s){
return s.size() > 2 && s.find_first_not_of("\r\n") != string::npos;
}) |
observe_on(tweetthread) |
rxo::map([](const string& line){
return make_shared<const json>(json::parse(line));
});
the complete function
inline auto parsetweets(observe_on_one_worker tweetthread)
-> function<observable<shared_ptr<const json>>(observable<string>)> {
return [=](observable<string> chunks){
// create strings split on \r
auto strings = chunks |
concat_map([](const string& s){
auto splits = split(s, "\r\n");
return iterate(move(splits));
}) |
filter([](const string& s){
return !s.empty();
}) |
publish() |
ref_count();
// filter to last string in each line
auto closes = strings |
filter(isEndOfTweet) |
rxo::map([](const string&){return 0;});
// group strings by line
auto linewindows = strings |
window_toggle(closes | start_with(0), [=](int){return closes;});
// reduce the strings for a line into one string
auto lines = linewindows |
flat_map([](const observable<string>& w) {
return w | start_with<string>("") | sum();
});
return lines |
filter([](const string& s){
return s.size() > 2 &&
s.find_first_not_of("\r\n") != string::npos;
}) |
observe_on(tweetthread) |
rxo::map([](const string& line){
return make_shared<const json>(json::parse(line));
});
};
}
algorithms for the win!
This is a fairly complex problem. We have chunks of text arriving over time and they need to be parsed so that json fragments that span chunks are stiched back together and multiple json documents in one chunk are split up. Writing all these algorithms in the raw using promises or callbacks would be a mess of code. Some simple algorithms can be composed to give the functionality with much less chance for confusion or error.